还在用 SSH 批量跑脚本?基于 K3s + Rancher Fleet 构建边缘网关“GitOps”零干预分发 (附 YAML 模板)
2026-03-17 11:33:00
#GitOps #K3s #RancherFleet #边缘计算 #大规模运维 #IaC #DevO
一、 场景痛点:更新 1000 台网关的“至暗时刻”
你的集成公司业务做得很成功,在全国 50 个工厂部署了 1000 台 AI 边缘网关(运行着采集脚本和 YOLO 质检模型)。
但噩梦才刚刚开始:
需求:今天算法团队把 YOLO 模型优化了一下,或者修改了 Node-RED 里的一个点表参数,需要更新到这 1000 台设备上。
现状:运维工程师写了一个 Ansible 脚本(或者自己写的 Python 批量 SSH 脚本),准备向这 1000 个 IP “推(Push)”送更新。
灾难现场:
NAT 穿透失败:这 1000 台设备分布在各种复杂的内网、4G 路由器和多层防火墙后面,中心端根本主动连不上它们(无法建立 SSH 连接)。
弱网超时:脚本跑到第 400 台时,有一台设备 4G 信号不好卡住了,整个批量脚本直接挂起报错。
配置漂移 (Configuration Drift):现场的电工有时会偷偷登录网关改配置。中心端以为网关跑的是 V2 版本,实际现场已经变成了面目全非的“魔改版”。
必须切换为 “拉取式 (Pull-based) GitOps”。网关只认 Git 仓库,Git 仓库就是唯一的真理之源 (Single Source of Truth)。
二、 架构设计:为什么选 Rancher Fleet?
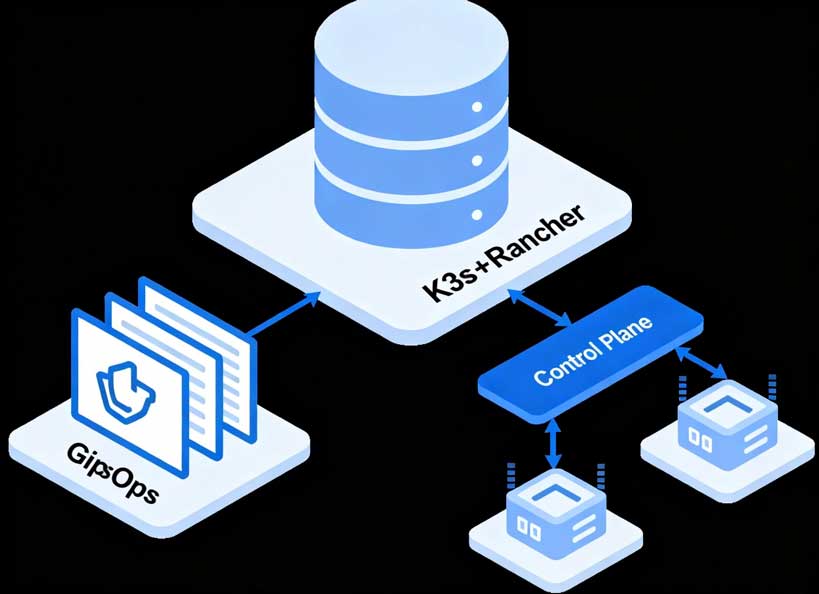
在 K8s 生态中,ArgoCD 是 GitOps 的绝对王者,但它适合**“一个集群里有 1000 个应用”的云端场景。在边缘端,我们的场景是“1000 个分散的微集群(每台网关就是一个单节点 K3s),跑同一个应用”**。此时,专门为百万级边缘集群设计的 Rancher Fleet 是最佳选择。
工作原理:
我们把应用的 YAML 配置(包含 Docker 镜像地址、版本号)全部提交到 GitHub/GitLab 仓库。
网关(运行 K3s + Fleet Agent)会主动定时向 Git 仓库(或本地的 Fleet Controller)发送 HTTPS GET 请求。
网关发现 Git 里的版本变了,主动把配置拉下来,并在本地执行应用重启。
优势:网关主动往外拉,完美穿透一切内网 NAT 防火墙。就算今天断网了,明天网关一上线,依然会自动同步到最新版本。
拓扑图:架构师 --(git push)--> [GitLab 仓库] <--HTTPS Pull--[Fleet Agent @网关 1...1000 (K3s)] -> 拉取新 Docker 镜像
三、 核心实施步骤 (Copy & Paste)
假设你已经有一台中心服务器运行了 Rancher/Fleet Controller,且边缘网关已安装好 K3s 并注册到 Controller。
1. 基础设施即代码 (IaC) 目录结构
在你的 Git 仓库中,创建如下结构,把配置当代码一样管理。
my-edge-apps/ ├── fleet.yaml # Fleet 核心路由配置 └── node-red-app/ ├── deployment.yaml # 业务容器定义 └── service.yaml
2. 定义容器配置 (deployment.yaml)
这是标准的 K8s 定义文件。你想跑什么,就在这里写。
apiVersion: apps/v1 kind: Deployment metadata: name: edge-node-red namespace: default spec: replicas: 1 selector: matchLabels: app: node-red template: metadata: labels: app: node-red spec: containers: - name: node-red # 当你需要升级时,只需在 Git 里把 v2.0 改为 v2.1 image: my-registry.com/edge-node-red:v2.1 ports: - containerPort: 1880
3. 编写 Fleet 路由规则 (fleet.yaml)
这是最爽的一步。你可以根据网关的标签 (Labels),决定哪个网关拉取哪个配置。比如“华东区的机器更新 A 版本,华北区的机器更新 B 版本”。
defaultNamespace: default labels: app: edge-data-collector # 目标网关匹配规则 targetCustomizations: - name: east-china-nodes clusterSelector: matchLabels: region: "east-china" # 只要网关带这个标签,就会自动拉取这个配置 yaml: # 可以在这里覆盖特定区域的配置,比如修改环境变量 overlays: - apiVersion: apps/v1 kind: Deployment name: edge-node-red spec: template: spec: containers: - name: node-red env: - name: MQTT_BROKER value: "tcp://east-mqtt.cloud.com"
在开发机敲下 git commit -m "Update to v2.1" 和 git push。
喝杯咖啡,全国 1000 台打了 region: east-china 标签的网关,会在 1 分钟内自动把 MQTT_BROKER 修改掉并重启容器。无需一次 SSH 登录。
四、 踩坑复盘 (Red Flags)
1. 镜像拉取风暴 (Image Pull Storm)
灾难:你把一个 2GB 的 AI 模型镜像推到了云端 Registry,并 git push 了更新。1000 台网关同时向云端拉取镜像。公司的公网带宽瞬间被打满,云服务器直接宕机。
对策:
金丝雀发布 (Canary Release):在 fleet.yaml 中利用 Rollout 策略,先给 5% 的标签节点更新,没问题再扩大。
P2P 镜像分发:在边缘端集成 Dragonfly (蜻蜓) 或 Kraken。网关从临近的网关采用 P2P 下载镜像,把中心带宽压力降到几乎为 0。
2. 密码泄露在 Git 里
坑:把数据库密码明文写在 YAML 文件里传到 Git,离职员工把代码拷走,引发重大安全事故。
对策:绝对严禁将 Secret 明文存入 Git。请使用 SOPS 或 Sealed Secrets。开发用公钥将密码加密后存入 Git(密文),只有网关上的 K3s 拥有私钥,可以在本地解密还原出密码。
3. 存储容量耗尽
现象:频繁发布更新后,网关的 32GB eMMC 满了,导致 K3s 驱逐所有的 Pod。
原因:旧的 Docker 镜像没有被清理。
对策:必须在 K3s 启动参数(/etc/rancher/k3s/config.yaml)中严格配置镜像垃圾回收(Image GC)阈值:
kubelet-arg: - "image-gc-high-threshold=80" - "image-gc-low-threshold=60"
五、 关联资源与选型
跑 K3s 和 Fleet Agent,网关不能用几十块钱的单片机,需要标准的 Linux 环境。
硬件推荐:
x86 边缘网关 (Intel J6412 / N100):如果你有很多基于 Python 的复杂容器,或者需要兼顾 HMI 屏幕输出,x86 是跑 K3s 最省心的选择。
点击配置完美兼容 K3s/K8s 的 x86 工业网关
ARM 高性能边缘盒子 (NXP i.MX8M Plus):具备极佳的功耗比,自带 NPU,适合将 AI 模型通过 GitOps 分发到成千上万个视觉检测节点。
查看支持云原生容器编排的 ARM 边缘主板
代码下载与工具
还没有搭建好中心控制端?
我们准备了一个 "Edge GitOps 快速体验环境"。
包含:Rancher Server 的一键 Docker-Compose 脚本、Fleet 的标准 YAML 模板、以及 Sealed Secrets 加密工具包。
架构师福利:下载 K3s+Fleet 边缘大集群分发套件

