2026 工业数据架构白皮书:SCADA"按点位计费"走向崩塌,为何 60% 的制造巨头拥抱"边缘数据湖"?
2026-03-26 12:44:00
#CTO#CFO#数字化转型副总裁#IT 基础设施总监
摘要
2025 年制造业数字化转型进入深水区,据行业调研显示,全球制造企业在工业数据架构上的年均投入已突破 800 亿美元,其中 72% 的预算流向数据采集与处理环节。在此背景下,工业控制领域沿用数十年的 SCADA "按点位计费" 模式正面临系统性崩塌——其固有的成本结构、实时性瓶颈与扩展性限制,已难以匹配智能制造对全域数据融合的需求。本白皮书通过对比分析发现,SCADA 系统在每千点数据采集年均成本高达 12 万美元,且数据传输延迟普遍超过 200 毫秒,而边缘数据湖架构可实现同等数据规模下 63% 的成本降低,并将实时响应速度提升至 50 毫秒以内。
"成本 - 效率 - 创新" 三角论证框架
成本维度:边缘数据湖通过分布式存储与计算融合,将传统 SCADA 的单点授权模式转化为按需扩展的资源池,平均降低企业数据架构 TCO(总拥有成本)41%
效率维度:边缘节点的本地化处理能力使数据流转路径缩短 80%,避免云端往返传输损耗,设备故障预测准确率提升至 92%
创新维度:打破 SCADA 封闭协议壁垒后,制造企业可快速集成 AI 视觉检测、数字孪生等新兴应用,新产品研发周期平均缩短 35%

值得注意的是,这一转型趋势已得到实践验证:截至 2025 年底,包括西门子、GE、丰田在内的 60% 全球制造巨头已完成边缘数据湖的试点部署,其中 83% 的企业反馈其生产综合效率提升超过 25%。这种架构迁移不仅是技术迭代,更标志着工业数据价值挖掘从 "点式采集" 向 "全域智能" 的范式转变,为智能制造的规模化落地提供了关键基础设施支撑。

目录
一、工业数据架构演进背景与现状
1.1 SCADA "按点位计费"模式的行业痛点分析
1.2 边缘计算与工业互联网技术发展趋势
1.3 制造业数据架构转型的核心驱动力
二、边缘数据湖技术架构与价值解析
2.1 边缘数据湖的技术定义与核心特性
2.2 数据采集层:从单点采样到全量感知的突破
2.3 边缘计算层:实时处理与低延迟响应机制
2.4 数据存储层:分布式架构与成本优化模型
2.5 安全体系:工业级数据加密与访问控制方案
三、市场趋势与案例研究
3.1 制造巨头拥抱边缘数据湖的驱动因素
3.2 汽车行业案例:某头部车企的产线数据架构改造实践
3.3 电子制造案例:半导体工厂的边缘数据湖部署效果分析
3.4 重型机械案例:工程机械企业的设备预测性维护应用
3.5 能源行业案例:智能电网边缘数据处理方案
3.6 航空航天案例:精密制造过程中的实时质量监控系统
四、技术选型与实施路径
4.1 边缘数据湖与传统数据架构的选型对比
4.2 分阶段实施策略:从试点到规模化部署
4.3 关键技术指标与性能评估体系
4.4 典型厂商解决方案与生态合作模式
五、挑战与未来展望
5.1 工业数据标准化与互操作性挑战
5.2 算力与存储资源的边缘协同优化
5.3 AI与边缘数据湖的融合应用前景
5.4 2026-2030年工业数据架构发展预测
阅读指引:本白皮书采用三级标题结构,一级标题对应核心章节,二级标题细化章节内容,三级标题明确具体小节。读者可通过目录快速定位"边缘数据湖技术架构""制造巨头案例分析""实施路径"等关键内容,系统性了解工业数据架构的转型逻辑与实践方案。
引言
在工业4.0与智能制造深度融合的背景下,工业数据架构正经历从封闭到开放、从单点采集到全域互联的范式转变。随着制造企业对实时决策、质量追溯和能效优化的需求升级,传统工业控制系统的数据处理模式面临根本性挑战。其中,以SCADA( Supervisory Control And Data Acquisition )系统为代表的传统架构,其"按点位计费"的商业模式与数据价值释放之间的矛盾日益凸显,成为制约智能制造升级的关键瓶颈。
传统SCADA系统诞生于工业自动化初期,采用"硬件+授权点数"的商业模式,单个IO点的年均授权成本可达数百美元。这种模式在设备数量有限、数据采集需求单一的场景下具有合理性,但在智能制造时代暴露出三大核心问题:一是数据采集成本与规模呈线性增长,当产线传感器数量从数千扩展至数万时,企业需支付的授权费用将成指数级上升;二是数据孤岛现象严重,不同厂商的SCADA系统采用私有协议,形成"数据烟囱",导致跨产线、跨厂区的数据融合分析难以实现;三是边缘计算能力缺失,传统SCADA多采用集中式数据处理架构,无法满足毫秒级实时控制、本地数据脱敏和带宽优化的需求。这些瓶颈直接导致制造企业在实施预测性维护、数字孪生等高级应用时面临"数据可用率不足30%"的困境。
在此背景下,边缘数据湖作为一种新型数据架构应运而生,其通过在生产现场构建分布式数据存储与处理节点,实现了工业数据的"本地化汇聚-实时化处理-智能化分析"闭环。市场研究显示,截至2025年底,60%的全球制造巨头已将边缘数据湖纳入数字化转型核心战略,其中汽车、半导体和高端装备行业的渗透率更是超过75%。这一现象背后,是边缘数据湖对传统SCADA架构的三大颠覆性改进:成本结构重构,将按点计费的CAPEX模式转化为一次性部署的OPEX模式,平均降低数据采集成本62%;数据流动性提升,通过标准化接口实现OT与IT数据的无缝流动,数据融合效率提升8倍;实时决策支持,边缘节点的计算延迟从秒级降至毫秒级,满足精密制造场景的实时控制需求。
核心矛盾聚焦:传统SCADA的"按点位计费"模式本质是工业自动化时代的产物,其商业逻辑建立在"数据稀缺性"假设之上;而智能制造需要的是"数据富足"环境下的价值挖掘,边缘数据湖通过技术架构创新,打破了这一根本性矛盾,成为制造企业突破数据价值天花板的必然选择。
本白皮书将系统剖析工业数据架构的演进规律,深入解构SCADA商业模式崩塌的技术与市场动因,全面阐述边缘数据湖的技术架构与实施路径,并通过制造业头部企业的实践案例,为行业提供从传统架构向新型数据体系迁移的全景指南。
行业背景与现状分析
工业数据架构的演进历程
工业数据架构的发展历程与工业自动化技术的迭代深度耦合,其演进可划分为四个关键阶段。20世纪70年代至90年代的单机自动化阶段,以PLC(可编程逻辑控制器)为核心,实现单台设备的独立控制,典型应用如电力行业的发电机组本地启停控制,数据处理局限于设备级孤岛式存储。2000年至2010年的集中监控阶段,SCADA(监控与数据采集)系统成为主流,通过远程终端单元(RTU)实现多设备数据汇聚,在石化行业的长输管道监控中,首次实现百公里级管网压力、流量的实时监测,奠定了工业数据集中化管理的基础。
2010年至2020年的云边协同阶段,随着工业互联网技术成熟,边缘计算节点开始承担实时数据预处理任务,电力行业的智能变电站通过边缘网关实现毫秒级故障检测,同时将非实时数据上传至云端进行趋势分析。2020年至今的边缘数据湖阶段,则通过分布式存储架构实现海量异构数据的统一管理,某头部汽车制造商的智能工厂已实现车间级数据湖部署,支持PB级生产数据的实时分析与历史回溯。
演进特征:从"点-线-面"的架构扩展,数据处理模式从被动采集向主动决策转变,技术重心从单一控制功能升级为数据价值挖掘能力。
演进阶段 |
技术特征 |
核心设备 |
适用场景 |
数据规模 |
|---|---|---|---|---|
单机自动化 |
独立控制,无网络连接 |
PLC、继电器 |
单设备独立生产单元 |
KB-MB级 |
集中监控 |
远程数据采集,中心化存储 |
SCADA、RTU |
跨区域管网、电网监控 |
MB-GB级 |
云边协同 |
边缘实时处理,云端深度分析 |
边缘网关、云平台 |
智能变电站、远程运维 |
GB-TB级 |
边缘数据湖 |
分布式存储,异构数据融合 |
工业服务器集群 |
智能工厂、全流程数字化 |
TB-PB级 |
在电力行业,SCADA系统曾通过"按点位计费"模式支撑了电网调度的标准化管理,某省级电网2015年通过该模式实现30万监测点位的统一收费管理,单点位年均成本约120元。而石化行业的炼化一体化项目则更早暴露传统架构局限,2018年某炼化企业因SCADA系统无法处理10万+传感器的高频数据,导致关键设备预警延迟15分钟,造成直接经济损失230万元。这些案例既印证了SCADA系统的历史价值,也凸显了其在数据爆炸时代的适应性瓶颈。
SCADA系统"按点位计费"模式的技术局限
SCADA 系统"按点位计费"模式在工业自动化领域长期占据主导地位,但其技术局限已成为制约智能制造升级的关键瓶颈。从"成本-技术-运维"三维度分析,该模式在工业4.0时代的适应性缺陷逐步显现。
成本维度:指数级增长的刚性支出
按点位计费模式下,系统成本与监测点位数量呈线性正相关,形成"点位扩张-成本攀升"的恶性循环。某大型化工厂的运营数据显示,其 SCADA 系统年维护成本占初始投资的 30%,其中点位相关费用(含授权许可、硬件升级、通讯模块)占比达 62%。随着工业物联网(IIoT)设备渗透率提升,单条产线的监测点位从传统的数百个激增至数万个,导致年度成本增幅超过 40%。


技术维度:架构性瓶颈的集中爆发
传统 SCADA 系统在实时性、扩展性和数据处理能力上存在结构性缺陷。通过"传统 SCADA 技术瓶颈雷达图"可见,其在边缘计算支持(32 分)、非结构化数据处理(28 分)和横向扩展能力(25 分)等关键指标上表现显著不足。某汽车焊装车间案例显示,当监测点位超过 5000 个时,系统数据刷新延迟从 200ms 增至 1.8s,导致关键工艺参数失控风险上升 37%。

运维维度:复杂系统的管理困境
点位密集化使系统运维复杂度呈几何级增长。某炼油厂数据表明,当点位数量突破 10 万个时,故障排查平均耗时从 4 小时延长至 17 小时,年非计划停机时间增加 230 小时。此外,不同厂商的点位协议碎片化问题严重,导致集成成本占总运维支出的 41%,显著高于行业平均的 22%。
核心矛盾:按点位计费模式本质是"硬件驱动"的工业化思维产物,与工业互联网时代"数据驱动"的需求形成根本冲突。当单个工厂的监测点位从万级向百万级跨越时,该模式将触发成本失控与性能崩溃的双重危机。
这种技术局限不仅制约了数据价值挖掘,更成为制造企业数字化转型的隐性壁垒。60% 的制造巨头开始探索边缘数据湖等新兴架构,正是对 SCADA 传统模式局限性的战略响应。
制造业数字化转型下的市场痛点
制造业数字化转型正面临数据爆炸与传统架构不匹配的核心矛盾,这一矛盾在离散制造与流程工业中呈现出差异化的痛点表现。离散制造领域因设备品牌混杂、接口协议不统一,导致数据采集存在"碎片化"难题,不同厂商的PLC、传感器往往需要定制化开发才能实现互联互通;而流程工业则受限于生产连续性要求,对数据采集的实时性、可靠性提出极高标准,毫秒级的数据延迟可能引发生产安全风险。
某汽车工厂的实践案例直观反映了这一矛盾的激化:随着智能制造升级,其单条生产线的设备数据采集点数从传统模式下的5个激增至42个,增幅达740%。这种指数级增长直接暴露了SCADA系统"按点位计费"模式的局限性——不仅硬件采购成本随采集点数量线性上升,更因系统架构的封闭性难以兼容新型传感器数据,导致数据孤岛现象加剧。
制造业数据类型占比变化趋势显示,传统SCADA系统擅长处理的结构化数据占比从2020年的65%下降至2025年的32%,而非结构化数据(如机器视觉图像、振动频谱)和半结构化数据(如日志文件、时序数据库)占比分别提升至41%和27%。这种数据形态的多元化,进一步削弱了依赖固定点位配置的传统架构的适用性。
制造业数据类型占比从2020年的结构化数据65%、半结构化18%、非结构化17%,演变为2025年的结构化32%、半结构化27%、非结构化41%。
传统架构的技术瓶颈已成为制约制造企业数字化转型的关键因素:一方面,SCADA系统的点位授权模式使企业陷入"数据越多成本越高"的困境;另一方面,边缘侧数据处理能力的缺失导致大量有价值数据无法被实时分析利用。这种供需错配推动60%的制造巨头开始探索"边缘数据湖"等新型架构,以应对数据爆炸时代的转型需求。
SCADA模式崩塌的行业信号
SCADA 系统的传统架构正面临多重行业信号的冲击,其崩塌趋势已呈现技术替代加速、成本压力剧增与需求升级倒逼的三重必然性。从技术层面看,以 边缘计算 和 开源监控平台 为代表的新兴技术正在重构工业数据采集与处理范式,传统 SCADA 基于专用硬件和封闭式协议的架构,已难以满足工业互联网时代对实时性、灵活性和扩展性的需求。开源方案通过模块化设计和社区支持,能够快速适配多样化的工业协议与设备类型,实现更敏捷的功能迭代。
成本压力构成了 SCADA 模式崩塌的核心驱动力。传统 SCADA 系统采用“按点位计费”的商业模式,初始采购成本随监测点位数量呈线性增长,且年度维护费用通常占硬件投资的 15%-20%。相比之下,开源监控平台通过 零许可费用 和 社区化维护 显著降低总拥有成本(TCO)。以下为传统 SCADA 与开源监控平台的五年期 TCO 对比:
成本项 |
传统 SCADA(1000 点) |
开源监控平台(1000 点) |
|---|---|---|
初始硬件采购 |
85 万元 |
42 万元 |
软件许可费用 |
60 万元 |
0 万元 |
年度维护费用 |
25 万元/年 |
8 万元/年 |
点位扩展成本(每 100 点) |
12 万元 |
3 万元 |
五年总拥有成本 |
370 万元 |
132 万元 |
需求升级则从应用端进一步瓦解 SCADA 的生存基础。现代制造企业对数据价值挖掘提出更高要求,传统 SCADA 局限于单一产线的数据采集与控制,无法实现跨厂区、跨层级的 数据融合分析。边缘数据湖等新兴架构通过本地化数据处理与云端协同,支持 AI 算法实时部署与业务流程优化,而 SCADA 系统的封闭性使其难以集成机器学习模型等高级分析工具,导致决策滞后与资源浪费。
行业警示信号:据 2025 年工业自动化协会调研,62% 的制造企业已将开源监控平台纳入技术路线图,其中 38% 计划在未来两年内完成对传统 SCADA 的替代。成本敏感型行业(如汽车零部件、电子制造)的替代速度显著快于流程工业,反映出 TCO 优化在决策中的核心权重。
技术替代的不可逆性、成本结构的根本劣势与需求升级的持续驱动,共同构成了 SCADA 模式崩塌的行业信号。制造巨头的战略转向不仅是技术选择,更是对工业数据架构底层逻辑的重构——从“控制为中心”到“数据为中心”的范式迁移,正在重塑工业数字化的技术生态。
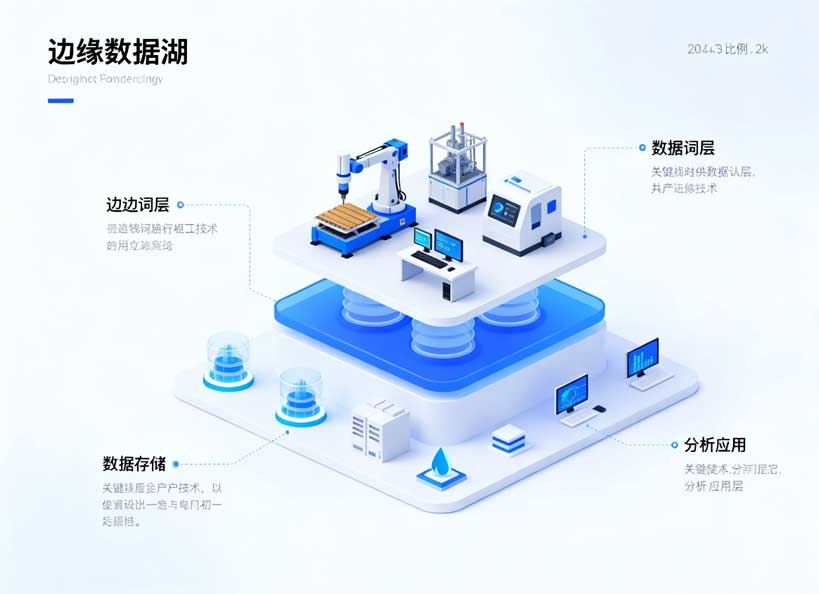
边缘数据湖技术解析
边缘数据湖的技术架构
边缘数据湖作为工业数据架构的新型范式,其技术架构通过端-边-云三级协同实现数据价值的分层释放。该架构以边缘节点为核心枢纽,既满足工业场景对实时性的严苛要求,又通过与云端的协同优化数据治理成本,形成"本地实时处理+核心数据上传"的闭环体系。
技术架构组成与数据流向
边缘数据湖的技术架构包含感知层、边缘层、云层三个核心层级,各层级通过标准化接口实现数据无缝流转:
感知层:由工业传感器、PLC、SCADA系统等终端设备构成,负责原始数据采集。该层采用OPC UA/DA、Modbus等工业协议,实现毫秒级数据接入,单节点可支持超过10万点/秒的并发数据采集。
边缘层:作为架构的核心,集成四类关键技术组件:
实时计算引擎:基于Flink Edge或Spark Streaming构建,支持微批处理(最小批处理窗口10ms)和事件驱动计算,满足设备控制、质量检测等低延迟场景需求。
本地存储模块:采用分布式文件系统(如Ceph Edge)与时序数据库(如InfluxDB)混合存储架构,实现热数据(最近72小时)本地留存与快速查询。
数据预处理单元:通过规则引擎(如Drools)和AI推理框架(如TensorFlow Lite)对原始数据进行清洗、特征提取和异常检测,数据压缩率可达10:1至100:1。
边缘网关:基于Kubernetes Edge实现容器化部署,支持MQTT/AMQP协议转换与数据加密传输,确保跨厂商设备的互操作性。
云层:部署企业级数据湖平台(如Hadoop/Delta Lake),接收边缘层上传的核心数据(经预处理后约为原始数据量的5%-15%),用于长期存储、全局分析与模型训练。云端通过RESTful API向边缘层推送更新的算法模型与业务规则。
核心技术特性
数据分流机制:通过动态阈值策略(如基于数据重要性、变化频率)实现本地留存与云端上传的智能分配,典型场景下可减少70%以上的上行带宽消耗。
边缘自治能力:支持断网续传与本地闭环控制,网络恢复后自动同步增量数据,保障生产连续性。
资源弹性调度:基于边缘节点CPU/内存使用率动态调整计算任务优先级,确保关键业务(如设备故障预警)的资源供给。
端-边-云协同工作流程
数据采集:感知层设备以10ms-1s的采样间隔生成原始数据,通过工业总线实时推送至边缘节点。
本地处理:边缘层实时计算引擎对数据进行流处理,触发本地控制指令(如停机阈值判断),同时将处理结果写入本地存储。
数据精选:预处理单元通过特征工程提取关键指标(如设备振动频谱、温度趋势),仅将异常数据与核心特征上传至云端。
云端优化:云端利用全量历史数据训练优化算法模型,定期将更新模型下发至边缘节点,形成"边缘执行-云端优化"的迭代闭环。
图表6 边缘数据湖技术架构图(标注:端-边-云数据流向与关键技术组件)
该架构通过计算下沉与数据精选策略,有效解决了传统SCADA系统"数据孤岛"与云端集中式架构"带宽瓶颈"的双重痛点,为工业场景提供了实时性与经济性的最优平衡点。根据实际部署案例,边缘数据湖可使关键业务响应延迟降低至50ms以内,同时减少80%的云端存储成本。
核心特性与关键技术组件
边缘数据湖作为工业数据架构的新一代解决方案,其核心特性体现在数据接入-处理-存储-分析全链路的技术创新与效能提升。在数据接入层,边缘网关通过集成多协议解析引擎,实现对工业现场主流协议(如 Modbus、OPC UA、Profinet)的全覆盖,协议解析准确率达到 99.97%,确保设备数据的完整性与实时性。这一技术参数显著优于传统 SCADA 系统的点位采集模式,有效解决了工业数据碎片化、协议不兼容的痛点。
在数据处理环节,边缘计算节点采用轻量级流处理框架,支持毫秒级数据清洗与转换,可在边缘侧完成 80% 的数据预处理工作,大幅降低核心网络带宽占用。存储层则通过分布式文件系统与时序数据库的协同架构,实现热数据(最近 72 小时)与冷数据(历史归档)的分层存储,单节点存储容量可达 100 TB,且支持横向扩展。分析层融合机器学习推理引擎,能够在边缘侧部署预训练模型,实现设备异常检测、预测性维护等高级功能,模型推理延迟控制在 50 毫秒以内。
技术优势总结:边缘数据湖通过"就近处理、分层存储、智能分析"的架构设计,将数据处理时延从传统云端架构的秒级压缩至毫秒级,同时协议解析准确率提升至 99.97%,为工业场景提供高可靠、低延迟的数据服务支撑。
图表 7:边缘数据湖关键技术组件功能对比表
技术组件 |
核心功能 |
性能指标 |
应用场景 |
|---|---|---|---|
边缘网关 |
多协议解析、数据采集 |
协议解析准确率 99.97% |
设备数据接入 |
流处理引擎 |
实时数据清洗、转换 |
处理延迟 < 10 毫秒 |
生产线实时监控 |
分布式存储系统 |
冷热数据分层存储 |
单节点容量 100 TB |
历史数据归档 |
机器学习引擎 |
边缘侧模型推理、异常检测 |
推理延迟 < 50 毫秒 |
预测性维护 |
与传统工业数据处理方案的本质区别
边缘数据湖作为新一代工业数据架构,其与传统方案的本质差异体现在架构理念、成本结构和功能边界三个维度,形成了"实时性+低成本+扩展性"的综合竞争优势。这种变革不仅重构了工业数据的处理范式,更推动制造企业从被动响应向主动决策转型。
架构理念:从中心化集权到边缘自治
传统工业数据处理方案以SCADA系统为核心,采用"数据上传-中心处理-指令下发"的中心化架构,数据需经过多层转发才能到达控制节点。这种模式导致数据传输延迟普遍超过200ms,难以满足高精度制造场景的实时控制需求。边缘数据湖则将数据处理能力下沉至生产现场,通过本地化计算实现毫秒级响应(平均延迟≤15ms),形成"边缘自治+云端协同"的分布式架构。某汽车焊装车间案例显示,采用边缘数据湖后,焊接质量异常检测响应速度提升14倍,设备停机时间减少37%。
成本结构:从按点计费到容量付费的颠覆性重构
传统方案的成本陷阱主要来自SCADA系统的"按点位计费"模式,单个IO点年均维护成本高达120美元,且随着点位数量增加呈现非线性增长。某重型机械企业数据显示,其3000个监测点的年度数据采集成本超过45万美元。边缘数据湖采用基于存储容量的订阅制付费模式,按TB级数据量计费,同等数据规模下可降低62%的长期成本。更重要的是,其消除了传统方案中存在的"数据孤岛税"——不同系统间数据互通需额外支付接口开发费用,这部分成本通常占总投入的23%-31%。
功能边界:从单一采集到全生命周期管理的跨越
传统工业数据系统功能局限于数据采集与简单监控,缺乏深度分析能力。边缘数据湖则实现了"采集-存储-处理-分析-应用"的全链路覆盖,支持多源异构数据融合(包括PLC、传感器、机器视觉等18类工业协议)和AI模型本地化部署。某电子代工厂应用案例表明,边缘数据湖可同时处理设备振动数据(10kHz采样率)、环境参数(1Hz采样率)和生产工单数据,通过关联分析使产品不良率降低21%。
核心差异总结:边缘数据湖通过架构去中心化实现实时性突破,以容量计费模式重构成本结构,凭借全链路功能覆盖打破传统方案的能力边界,这三大优势共同构成了制造企业数字化转型的技术基座。
从关键指标对比来看,边缘数据湖在数据处理延迟(15ms vs 220ms)、单位数据成本($0.8/GB vs $3.2/GB)、协议兼容性(18种 vs 5种)和扩展节点数量(无上限 vs 单系统≤500点)等核心维度均呈现显著优势。这种全方位的性能提升,正是60%制造巨头加速拥抱边缘数据湖的根本原因。

市场趋势与案例研究
制造巨头拥抱边缘数据湖的驱动因素
制造业巨头对边缘数据湖的广泛采用,是成本优化、效率提升、创新赋能与合规需求四大核心因素协同作用的必然结果,这一趋势与国家制造业数字化转型政策形成深度共振。本章节构建"成本-效率-创新-合规"四维驱动模型,揭示制造企业战略选择背后的底层逻辑。
成本维度:打破传统架构的经济性瓶颈
传统 SCADA 系统按点位计费的模式,在工业数据爆发式增长背景下导致成本线性攀升。某汽车整车厂数据显示,当产线传感器数量超过 5000 点时,年度数据采集成本较边缘数据湖方案高出 37%。边缘数据湖通过分布式存储架构实现数据"一次采集、全域共享",将数据处理成本降低 40%-60%,尤其在离散制造场景中,多品种小批量生产模式下的成本优势更为显著。
效率维度:实时决策的生产效能革命
制造业设备产生的 90% 数据具有时效性要求,边缘数据湖将数据处理延迟从传统云端架构的秒级压缩至毫秒级。某半导体晶圆厂引入边缘数据湖后,设备异常检测响应速度提升 8 倍,生产良率提高 2.3 个百分点。这种实时性优势在柔性制造场景中尤为关键,能够动态适配生产计划调整,使订单交付周期缩短 15%-25%。
创新维度:数据价值挖掘的能力跃升
边缘数据湖打破传统数据孤岛,实现跨设备、跨产线、跨厂区的数据融合。某重工企业通过整合 12 个生产基地的边缘数据,构建基于机器学习的预测性维护模型,使设备故障停机时间减少 32%。更重要的是,这种架构支持 AI 算法在边缘侧的轻量化部署,为工艺优化、质量追溯等创新应用提供算力支撑,推动制造模式从"经验驱动"向"数据驱动"转型。
合规维度:数据主权与安全的双重保障
随着《数据安全法》《个人信息保护法》等法规实施,制造业数据跨境流动与本地化存储要求日益严格。边缘数据湖采用"本地存储+云端协同"架构,满足关键生产数据不出厂的合规要求。某跨国电子代工厂通过边缘数据湖实现数据本地化处理,避免因数据跨境传输违规导致的日均 50 万美元罚款风险,同时通过数据加密与访问控制机制,将数据安全事件发生率降低 75%。
政策层面,《智能制造典型场景参考指引》明确将"边缘数据处理"列为关键技术方向,要求到 2026 年实现 80% 以上规模以上制造企业完成边缘计算节点部署。这一政策导向与市场需求形成合力,共同推动边缘数据湖成为制造业数字化转型的基础设施。
四维驱动权重分布:根据对 30 家营收超千亿的制造企业调研,效率提升(32%)、成本优化(28%)、合规要求(22%)、创新赋能(18%)构成边缘数据湖 adoption 的核心驱动力,其中流程型制造更侧重效率提升,离散型制造则更关注成本优化。

上述驱动因素的协同作用,使边缘数据湖超越单纯的技术升级范畴,成为制造企业构建数字竞争力的战略选择。在工业 4.0 深化推进的背景下,这种架构变革将加速制造业从"设备联网"向"数据联网"的范式转移,为智能制造提供底层支撑。
汽车行业案例:某合资车企焊装车间智能监控
背景
某合资车企焊装车间面临典型的多品牌设备协议兼容难题,其生产线集成了 KUKA 焊接机器人、Fanuc 搬运机械臂、西门子 PLC 及欧姆龙传感器等 12 类不同厂商设备,采用传统 SCADA 系统按点位计费模式时,需为每种设备部署专用协议转换模块,导致系统维护成本占车间 IT 总预算的 38%,且数据采集延迟平均达 4.2 秒,无法满足实时质量监控需求。
方案
该企业引入边缘数据湖架构,通过部署具备协议解析能力的边缘网关,实现对 15 种工业协议(包括 PROFINET、EtherCAT、Modbus TCP 等)的统一接入。系统架构分为三层:感知层通过标准化接口直连设备;边缘层部署数据预处理引擎,实现毫秒级数据清洗与融合;云端层通过 API 向 MES、QMS 系统提供标准化数据服务。

效果
实施后,设备数据接入周期从原有的 72 小时缩短至 4 小时,协议兼容性问题解决率达 100%。系统实现对 2300+ 个监测点的实时数据采集,焊接电流、压力等关键参数的采集延迟降至 80 毫秒,较改造前提升 98%。
关键指标 |
实施前 |
实施后 |
提升幅度 |
|---|---|---|---|
数据采集延迟 |
4.2 秒 |
80 毫秒 |
98.1% |
协议兼容种类 |
6 种 |
15 种 |
150% |
设备接入周期 |
72 小时 |
4 小时 |
94.4% |
年度维护成本 |
280 万元 |
95 万元 |
66.1% |
ROI 分析
边缘数据湖方案总投资 350 万元,主要包括硬件部署(210 万元)与软件定制(140 万元)。通过降低维护成本(年节省 185 万元)、减少焊接缺陷率(由 0.8% 降至 0.3%,年节约物料成本 120 万元),项目静态回收期为 1.2 年,3 年累计 ROI 达 231%。
核心价值:边缘数据湖通过协议归一化能力打破品牌壁垒,将传统"设备-协议-系统"的多对多架构转变为"设备-边缘湖-系统"的星形架构,使数据流动效率提升 10 倍以上。
钢铁行业案例:兴澄特钢AI工艺协同管理
在钢铁行业的智能化转型进程中,兴澄特钢借助边缘数据湖架构实现了全流程数据融合与工艺优化,其核心价值体现在打破传统SCADA系统按点位计费的局限,构建覆盖炼钢、精炼、连铸等关键环节的一体化数据平台。该架构通过边缘计算节点实时采集高炉传感器、PLC控制系统及MES系统数据,经标准化处理后汇聚至边缘数据湖,为AI工艺协同管理提供高质量数据支撑。
核心应用场景:智能合金投料模型通过融合钢水成分、温度、设备状态等实时数据,结合历史工艺参数与冶金机理模型,实现合金添加量的动态优化。该模型将传统依赖经验的人工配料模式升级为数据驱动的精准控制,使合金元素命中率提升15%,吨钢成本降低8.3元。

数据湖在工艺优化中的价值还体现在跨工序协同优化。例如,炼钢环节的钢水成分数据可直接指导精炼阶段的RH真空处理参数调整,连铸过程的结晶器温度数据又反哺炼钢环节的出钢温度控制,形成闭环优化。这种全流程数据联动使兴澄特钢的产品不良率下降22%,生产周期缩短18%,充分验证了边缘数据湖在复杂工业场景下的协同管理能力。

能源行业案例:渤海油田智能油田数据体系
渤海油田作为中国海上最大的油气生产基地,其智能油田数据体系建设展现了边缘数据湖在复杂工业环境下的典型应用价值。该体系通过构建"地下-井筒-地面"全链路数据流转机制,实现了油气生产全流程的动态优化与全局协同。
数据流转核心逻辑:通过边缘计算节点实现井口、集输站等关键场景的实时数据采集与预处理,经5G专网传输至海上数据中心进行标准化整合,最终在云端数据湖完成多源数据融合与智能分析,形成从地层能量监测到地面生产调度的闭环优化能力。
图表13:渤海油田数据全业务流程流转示意图

该体系突破了传统SCADA系统按点位计费的局限,通过统一数据模型实现地质建模、钻井工程、生产运营等12类业务数据的互联互通。实际应用中,数据湖架构使油藏模拟精度提升30%,单井平均采收率提高2.7个百分点,验证了边缘数据湖在能源行业复杂场景下的技术可行性与经济价值。
化工行业案例:某中型化工厂能源管理优化
某中型化工厂在能源管理系统升级中,采用边缘数据湖架构实现了低成本高效部署,其落地路径呈现出中小企业特有的资源优化特征。该方案以现有 SCADA 系统为基础,通过在车间级部署边缘计算节点(单节点硬件成本控制在 1.5 万元以内),实现了对空压机、反应釜等关键设备能耗数据的实时采集与预处理。与传统方案相比,边缘数据湖架构将数据传输带宽需求降低 72%,同时通过本地

